

商湯發布NEO架構 重新定義多模態模型效能邊界
商湯科技發布並開源了與南洋理工大學S-Lab合作研發的全新多模態模型架構——NEO,為日日新SenseNova多模態模型奠定了新一代架構的基石。

作為行業首個可用的、實現深層次融合的原生多模態架構 (Native VLM),NEO從底層原理出發,打破了傳統「模組化」範式的桎梏,以「專為多模態而生」的創新設計,通過核心架構層面的多模態深層融合,實現了性能、效率和通用性的整體突破,重新定義了多模態模型的效能邊界,標誌著人工智能多模態技術正式邁入「原生架構」的新時代。

打破瓶頸 告別「拼湊」 擁抱「原生」
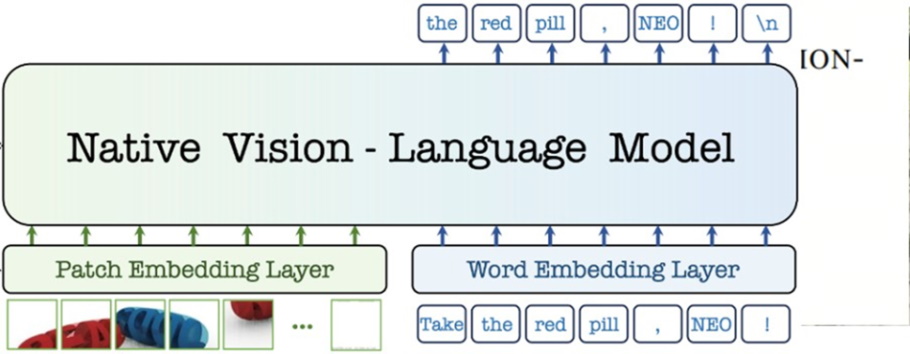
當前,業內主流的多模態模型大多遵循「視覺編碼器+投影器+語言模型」的模組化範式。這種基於大語言模型(LLM)的擴展方式,雖然實現了圖像輸入的兼容,但本質上仍以語言為中心,圖像與語言的融合僅停留在數據層面。這種「拼凑」式的設計不僅學習效率低下,更限制了模型在複雜多模態場景下(比如涉及圖像細節捕捉或複雜空間結構理解)的處理能力。
商湯NEO架構正是為了解决這一痛點而生。早在2024年下半年,商湯便在國內率先突破多模態原生融合訓練技術,以單一模型在SuperCLUE語言評測 和OpenCompass多模態評測中奪冠,並基於這一核心技術打造了日日新SenseNova 6.0,實現多模態推理能力領先。
之後,在2025年7月發布日日新SenseNova 6.5通過實現編碼器層面的早期融合,把多模態模型性價比提升3倍,並在國內率先推出商用級別的圖文交錯推理。商湯此次更進一步,徹底摒棄了傳統的模組化結構,從底層原理出發,推出了從零設計的NEO原生架構。
三大內核創新 實現視覺和語言的深層統一
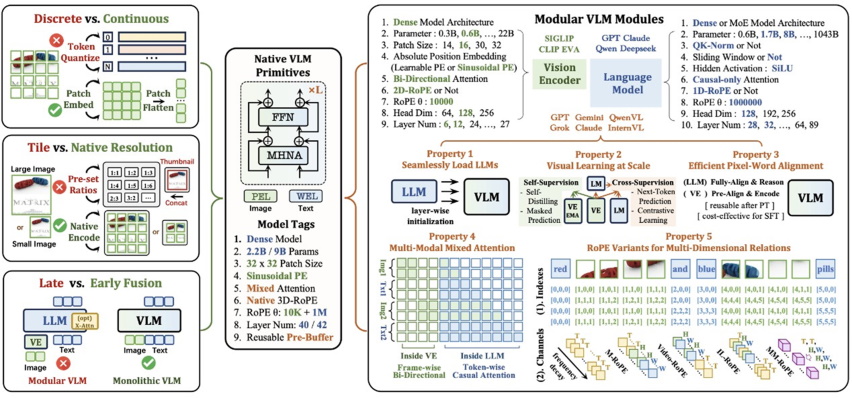
NEO架構以極致效率和深度融合為核心理念,通過在注意力機制、位置編碼和語義映射三個關鍵維度的底層創新,讓模型天生具備了統一處理視覺與語言的能力:
原生圖塊嵌入 (Native Patch Embedding): 摒棄了離散的圖像tokenizer,通過獨創的 Patch Embedding Layer (PEL) 自底向上構建從像素到詞元的連續映射。這種設計能更精細地捕捉圖像細節,從根本上突破了主流模型的圖像建模瓶頸。
原生三維旋轉位置編碼 (Native-RoPE): 創新性地解耦了三維時空頻率分配,視覺維度采用高頻、文本維度採用低頻,完美適配兩種模態的自然結構。這使得NEO不僅能精准捕獲圖像的空間結構,更具備向視頻處理、跨幀建模等複雜場景無縫擴展的潛力。
原生多頭注意力 (Native Multi-Head Attention): 針對不同模態特點,NEO在統一框架下實現了文本token的自回歸注意力和視覺token的雙向注意力並存。這種設計極大地提升了模型對空間結構關聯的利用率,從而更好地支撑複雜的圖文混合理解與推理。
此外,配合創新的Pre-Buffer & Post-LLM 雙階段融合訓練策略,NEO能夠在吸收原始LLM完整語言推理能力的同時,從零構建强大的視覺感知能力,徹底解决了傳統跨模態訓練中語言能力受損的難題。
實測表現:十分之一的數據,追評旗艦級性能
在架構創新的驅動下,NEO展現出了驚人的數據效率與性能優勢:
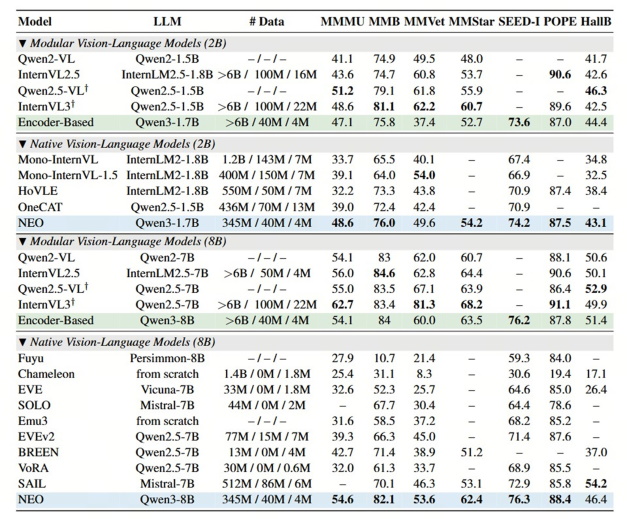
極高數據效率:僅需業界同等性能模型1/10的數據量(3.9億圖像文本示例),NEO便能開發出頂尖的視覺感知能力。無需依賴海量數據及額外視覺編碼器,其簡潔的架構便能在多項視覺理解任務中追平Qwen2-VL、InternVL3等頂級模組化旗艦模型。
性能卓越且均衡:在MMMU、MMB、MMStar、SEED-I、POPE 等多項公開權威評測中,NEO架構均斬獲高分,展現出優於其他原生VLM的綜合性能,真正實現了原生架構的「精度無損」。
極致推理性價比:特別是在0.6B-8B的參數區間內,NEO在邊緣部署方面優勢顯著。它不僅實現了精度與效率的雙重躍遷,更大幅降低了推理成本,將多模態視覺感知的「性價比」推向了極致。
開源共建,構建下一代AI基礎設施
架構是模型的「骨架」,只有骨架扎實,才能支撑起多模態技術的未來。NEO架構的早期融合設計支持任意分辨率與長圖像輸入,能夠擴展至視頻、具身智能等前沿領域,實現了從底層到頂層、端到端的真正融合。
從應用角度,端到端的「原生一體化」設計,為機器人具身交互、智能終端多模態響應、視頻理解、3D交互及具身智能等多元化場景的應用,提供了堅實的技術支撑。
目前,商湯已正式開源基於NEO架構的2B與9B兩種規格模型,以推動開源社區在原生多模態架構上的創新與應用。
商湯科技表示,致力於通過開源協作與場景落地雙輪驅動,將NEO打造為可擴展、可復用的下一代AI基礎設施,推動原生多模態技術從實驗室走向廣泛的産業化應用,加速構建下一代産業級原生多模態技術標準。