

大模型時代須重視數據和安全治理
在生成式人工智能 (Generative AI) 時代,越來越多人認識到善用它會提高生產力。對於大部分企業來說,生成式AI轉型過程中,最需要關心的不是GPU、推理成本及人力成本,而是數據和安全的治理。因為GPU和人力成本可控,且推理成本以每年約10倍的速度降低,而數據和安全的治理,首先是缺乏足夠的重視,其次是即使重視也很難做得好。
先來看看數據治理。生成式AI的創新,取決於強大的數據治理。數據是大模型的核心,兩者相互依存;而大模型亦需要大量高質量的數據進行訓練。
良好的數據治理可提供優質數據
良好的數據治理,可以將更好的數據餵養大模型,從而提升其性能。數據治理通過數據融合與清洗,企業可將多源多模態數據,整合為統一的數據視圖,一併發現與修複數據中的錯誤,從而解決大模型訓練中,數據多而分散、質量參差不齊的問題。

此外,大模型本質上是一個統計模型,容易產生不穩定性。數據治理可以通過知識圖譜和向量數據庫來緩解這個矛盾,提高大模型的可控性和可解釋性。
數據治理的成功關鍵
業界EDM Council的「雲端數據管理能力框架」(CDMC,Cloud Data Management Capability) 或國際數據管理協會 (DAMA) 的「數據管理知識體系」(DMBoK,Data Management Body of Knowledge),可以作為不錯的參考。藉助它們,企業從業務需求出發,而不是單純從技術角度出發,建立企業級的數據治理頂層設計,瞭解數據治理能帶來的降本增效、風險控制等實際價值。
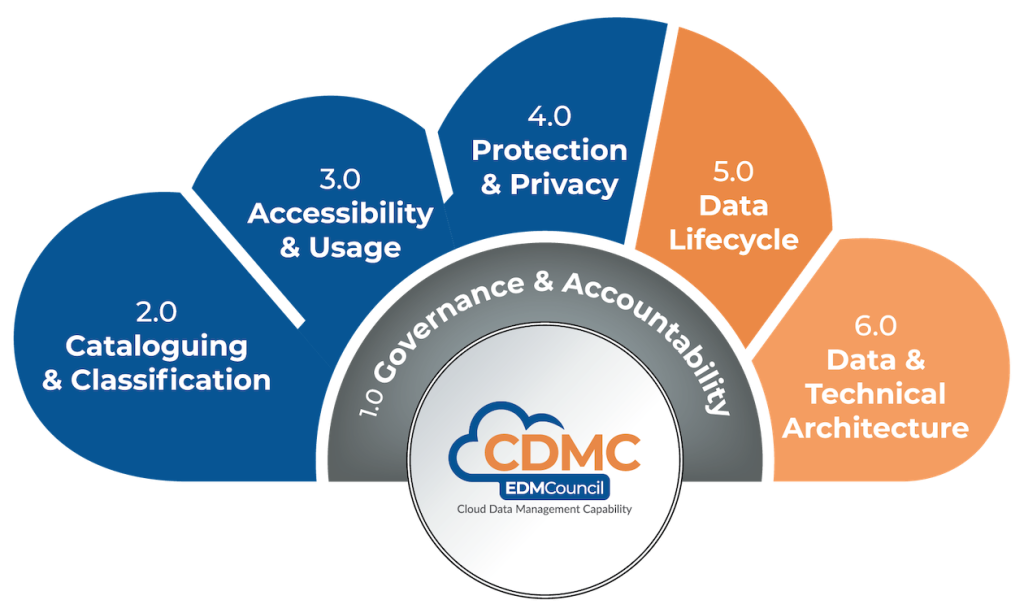
企業應從全局視角制定數據治理戰略,統籌規劃和協調各部門的數據治理工作,而不是局限於單一部門或項目。同時也要加強數據治理人員的業務理解和溝通協調能力。數據治理不僅需要技術支持,更需要深入理解業務需求,並與各部門有效溝通協調。
應致力提升大模型的安全性
另外,大模型的安全性,關係到其應用的可靠性和用戶的信任。只有避免大模型的偏見和隱私洩露,增強其防範能力,才能真正推動業務創新。大模型較為脆弱,容易受到指令攻擊、提示注入和後門攻擊等惡意攻擊,這對於金融、醫療、電信、交通等關鍵的行業和部門,尤為重要。
企業可以關注「開放網絡軟體安全計劃」(OWASP) 的大模型應用程式的十大風險 (Top 10 for Large Language Model) 的文檔。它由近500名國際安全專家和組織共同維護和完善。該文檔列出了LLM應用中,最關鍵的10大漏洞,包括提示注入、數據洩露、不充分的沙箱化、未經授權的代碼執行等。該文檔還提供了緩解和預防這些漏洞的具體策略。
風險管理的指南參考
對於風險管理,美國國家標準技術研究所 (NIST) 除了有AI風險管理框架 (AI RMF) 外,還有AI 600-1文件。它是一份大模型風險管理的指南文件,旨在幫助組織識別和管理大模型帶來的獨特風險。文件中列出了13個大模型風險,提供了400多個可採取的風險管理措施,涵蓋了大模型在設計、開發、使用和評估等各個階段的風險。
此外,中國工信部於2022年發布了《人工智能安全標準體系建設指南》,香港政府也於2023和2024年分別發布了《香港人工智能道德及安全指引》和《香港人工智能安全風險管理框架》,為香港的人工智能應用提供了風險管理的參考。這份框架與NIST的AI RMF,在結構和方法上,有一定對應關係。未來.隨著人工智能技術的發展,相信會有更多針對性的指南出台。總而言之,數據治理和資訊安全風險管理,決定了企業大模型的經濟和社會價值,用得好,必將事半功倍。
作者簡介:香港電腦學會企業架構專家小組執行委員會成員陳曉煒博士
