
Meta AI模型支援200種語言
為協助人們建立更好的聯繫,並於未來進入元宇宙,Meta AI 研究人員展開了「不遺下任何語言」(No Language Left Behind, NLLB)項目,致力為全世界大部分的語言開發高質素的機械翻譯功能。 NLLB-200單一 AI模型,能翻譯 200 種不同語言並取得最佳的成果。目前現有的最佳翻譯工具中,只能支援少於 25 種非洲語言,仍有許多語言(如坎巴文)沒有完善支援。而NLLB-200支援55種非洲語言,並能夠提供高質素的翻譯成果。

NLLB-200的雙語替換評測分數(BLEU score)在FLORES-101基準的所有 10,000 個方向中,較現有的先進翻譯工具分數平均提升了44%。在部分非洲和印度語言中,提升幅度相較最新的翻譯系統更提升了70%。
Meta 現在已開放 NLLB-200 模型的原始碼並發佈一系列研究工具,讓其他研究人員能夠將此作為基礎並擴大支援至更多語言,以及開發更具包容性的技術。此外,Meta AI亦向非牟利組織提供多達 $200,000 美元的補助金,以推廣NLLB-200的實際應用。
NLLB 的研究進展將支援 Facebook 動態消息、Instagram 和我們其他平台上每日所提供超過250億則翻譯內容。此外,支援更多語言的超精準翻譯還能協助辨別有害內容和錯誤資訊、維護廉正選舉,以及遏制網絡性剝削和人口販賣的情況發生。
為超過十億人提供翻譯工具
NLLB與主辦維基百科及管理其他免費知識項目的非牟利組織維基媒體基金會(Wikimedia Foundation)攜手合作,致力改善維基百科的翻譯系統。維基百科有超過 300 種語言版本,但多數語言版本所提供的文章數量遠少於英文版本所提供的超過 6 百萬篇文章。對於主要在歐洲和北美洲以外地區所使用的語言來說,這差距更顯著。
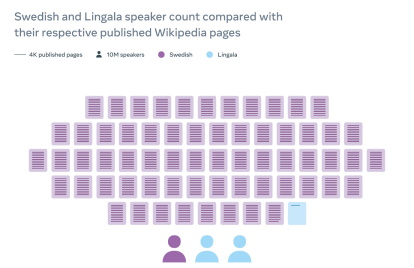
維基百科的編輯現在正透過維基媒體基金會(Wikimedia Foundation)內容翻譯工具使用NLLB-200模型背後的技術,將文章翻譯成超過 20 種資源匱乏的語言(這些語言沒有可用於訓練 AI 系統的大量數據庫),其中包括先前在該平台上沒有任何機械翻譯工具提供支援的 10 種語言。
為數百種語言建立單一模型的挑戰
就像所有 AI 模型一樣,機械翻譯系統需要數據來進行訓練。對文字翻譯系統而言,這通常包括數百萬個在多種語言之間仔細配對的句子。現有的翻譯模型嘗試透過從網絡挖掘數據來克服這個問題,但因為每種語言的文字來源不同,這些數據經常充斥著錯誤或不一致的拼法,並且遺漏重音符號和其他變音符號。
另一個重大挑戰是,必須在不影響效能的情況下對單一模型進行優化,以在數百種語言之間能夠順利運作。一直以來,最佳翻譯質素都是來自針對每個語言方向建立單獨的模型,但只要新增更多語言,效能和翻譯質素便會下降,因此難以擴大規模。一般來說,資源匱乏的語言擁有較少基準和數據庫,導致測試和完善模型的工作更困難。
結構、數據來源、基準分析創新
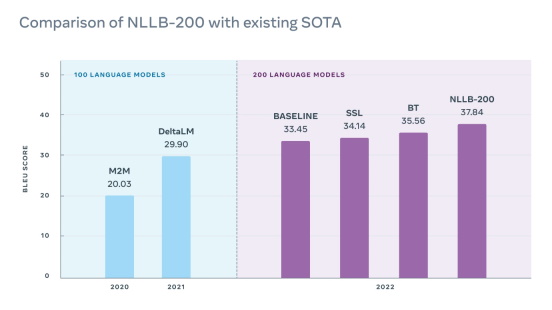
近年來,我們在克服上述挑戰時獲得了穩定的進展。2020Meta年發佈了100 種語言的 M2M-100 翻譯模型,這個模型利用全新的方法來取得訓練數據,在無損效能的情況下以新的結構擴大模型規模,並採用新的方式來評估和改善翻譯成果。為了擴大至另外 100 種語言,在這三個領域均取得進一步的進展。
擴大模型規模 維持高效能
多語言翻譯系統提供兩大優勢。這類系統能夠讓近似的語言在訓練期間共用數據。此外,研究人員在使用單一多語言模型進行修正、擴大規模和實驗時,會比使用數百或數千個不同雙語言模型更加容易。不過,仍存在重大挑戰。我們透過三方面的創新技術解決這些問題:正規化與課程學習、自我監督學習及多樣化的反向翻譯。
首先,開發具有共享且專用數據容量的專家混合(mixture-of-experts)網絡,以此將數據不多、資源匱乏的語言自動轉送至共用的數據容量,而只要與設計良好的正規化系統結合,便能避免過度配對。接著,由於資源匱乏的語言平行結構雙語料數據量較少,同時針對資源匱乏的語言和相似且擁有大量資源的語言,進行單語言數據的自我監督學習,以提升整體模型的效能。最後,我們分析如何透過最佳方式產生反向翻譯數據,發現將雙語言統計機械翻譯模型與多語言神經機械翻譯模型所產生的反向翻譯數據混合,能夠提升資源匱乏語言的效能,這歸功於產生的合成數據增加了多樣性。
適用於 200 種語言的評估和緩解工具
為評估和改善 NLLB-200,Meta建立了 FLORES-200多對多評估數據庫,讓研究人員可以評估40,000個不同語言方向的效能。我們將開放這個新數據集的原始碼,藉此協助其他研究人員迅速測試及改善他們的翻譯模型。FLORES-200可用於評估各種應用的翻譯系統,包括在使用資源匱乏語言的國家或地區內的健康小冊子、電影、書籍和網上內容。擴大至 200 種語言必須解決產生負面內容的風險,NLLB對所有支援的語言建立了負面內容清單,以便偵測並篩選出可能具冒犯性的內容,藉此解決這個問題。
擴展翻譯範圍提升包容性
高質素的翻譯工具可以帶動革新。相信 NLLB 有助於保留語言,因為它的設計為共用性質,而不是透過在情感或內容上經常發生錯誤的語言媒介。這個項目亦有助推動翻譯以外其他 NLP 工作的進展,包括建立能以爪哇文和烏茲別克文等語言順利運作的助理,或是建立能將波里活電影加上準確的斯瓦西里文或奧羅莫文字幕的系統。隨著元宇宙開始逐漸成形,建立能夠以數百甚至數千種語言順利運作的技術能力,將有助大家在虛擬世界中獲取全新的沉浸式體驗。
幾年前,高質素的機械翻譯只能在少數語言中運作。有了 NLLB-200,我們更接近擁有使人們能夠與任何人進行溝通的系統。隨著我們繼續突破機械翻譯的界限,我們對現在已創造的新機會,以及未來發展的重大意義感到萬分期待。