

百度CTO王海峰:大語言模型具備AI四項基礎能力
百度技術長、深度學習技術及應用國家工程研究中心主任王海峰,在9月21日清華大學舉行的「人工智慧賦能高品質發展」主題大會上,發表《人工智慧技術生態與產業模式》演說。王海峰表示,人工智慧具有多種典型能力,理解、生成、邏輯、記憶是其中的核心基礎能力,這四項能力越強,越接近通用人工智慧,而大語言模型具備了這四項能力,為發展通用人工智慧帶來曙光。
人工智慧進入工業大生產階段
早在2019年,王海峰曾提出,深度學習具有很強的通用性,並具備標準化、自動化和模組化的工業大生產特徵,推動人工智慧進入工業大生產階段。四年來,深度學習技術和應用的發展充分驗證了這個觀點。深度學習技術的通用性越來越強,深度學習平台的標準化、自動化和模組化特徵越來越顯著,而預訓練大模型的興起,使得人工智慧應用的深度和廣度進一步拓展,技術生態更加完善。人工智慧已進入工業大生產階段。
標準化方面,框架與模型共同優化,多硬體統一適配,應用模式簡潔高效,大幅降低人工智慧應用門檻;自動化方面,從訓練、適配,到推理部署,提升人工智慧研發全流程效率;模組化 方面,豐富的產業級模型庫,支撐人工智慧在廣泛場景的便利應用。
據了解,由於飛槳產業級深度學習開源開放平台和文心大模型的互相促進,貫通了深度學習全產業鏈,飛槳生態愈加繁榮,已凝聚800萬開發者,服務22萬家企事業 單位,基於飛槳創建了80萬個模型。 伴隨大模型的發展,百度推出了星河大模型社區,寓意「文心加飛槳,翩然赴星河」,與開發者共享共創大模型生態。
王海峰表示,人工智慧具有多種典型能力,理解、生成、邏輯、記憶是其中的核心基礎能力,這四項能力越強,越接近通用人工智慧,而大語言模型具備了這四項能力,為 發展通用人工智慧帶來曙光。
具體而言,人工智慧的典型能力如創作、程式設計、解題、規劃等都依賴理解、生成、邏輯、記憶等核心基礎能力,依賴程度有所不同。 以解題為例,從讀懂題目、解答題目到最後寫出答案,需要理解、記憶、邏輯及生成能力的綜合運用。
純中文模型生成能力強,理解和邏輯能力弱
知識增強大語言模式文心一言充分驗證了這一點。在訓練資料規模和參數規模相同的情況下,純中文模型比多語言模型生成能力強,理解和邏輯能力弱。文心一言首先從數萬億數據和數千億知識中融合學習得到預訓練大模型,在此基礎上採用有監督精調、人類反饋的強化學習和提示等技術,並具備知識增強、檢索 增強和對話增強等技術優勢。 在檢索增強和知識增強的基礎上,透過知識點增強,提升對世界知識的掌握和運用;透過邏輯資料建構、邏輯知識建模、多粒度語義知識組合以及符號神經網絡,提升邏輯推理能力。進一步地,透過多種策略優化資料來源及資料分佈、基礎模型長文建模、多類型多階段有監督精調、多任務自適應有監督精調、多層次多粒度獎勵模型等技術創新,全面 提升基礎通用能力。
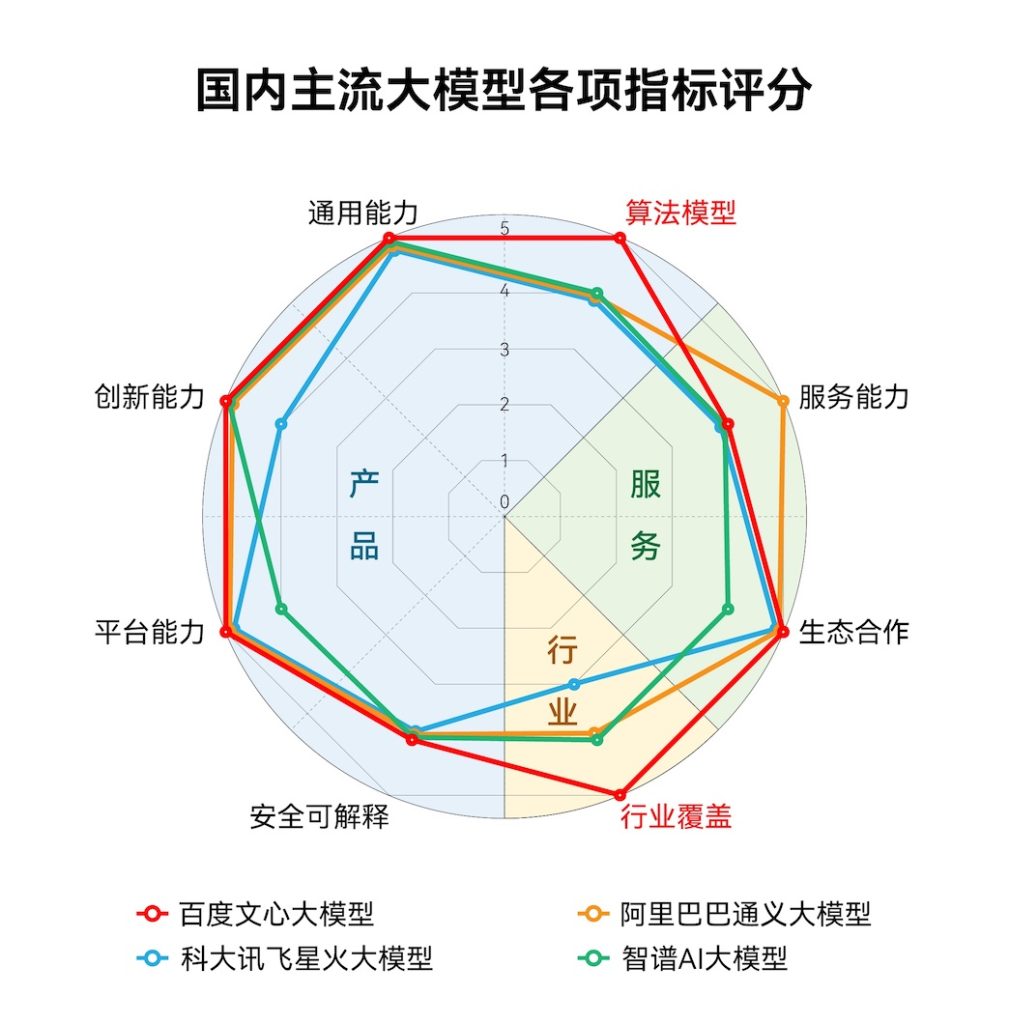
效率方面,透過飛槳端對端自適應混合併行訓練技術以及壓縮、推理、服務部署的協同優化,文心大模型訓練速度達到原來的3倍,推理速度達到原來的30多倍。 根據人民數據、新華網等多個公開測評,文心大模型3.5支持下的文心一言綜合能力超過ChatGPT,遙遙領先國內其他大模型。IDC《AI大模型技術能力評估報告,2023》顯示,文心大模型3.5拿下12項指標的7個滿分,得到「綜合評分第一,演算法模型第一,產業涵蓋第一」三個絕對第 一。
應用方面,透過資料驅動、提示構建,以及插件增強進行場景適配,協同優化。 文心一言已上線百度搜尋、覽卷文件、E言易圖、說圖解畫、一鏡流影等原生插件,使模型具備產生即時準確資訊、長文本摘要和問答、數據洞察和圖表製作、圖片為基礎的創作和問答、文生影片等能力。插件機制擴展了大模型能力邊界,更適應場景需求。
文心一言首日回答3342萬個問題
數據顯示,文心一言在8月31日率先面向全社會開放服務,首日回答了網友3342萬個問題,細分應用場景豐富,包括文案創意、教育諮詢、代碼生成等,目前已有15 萬企業和2萬多插件開發者申請接入。
面對大模型產業化的挑戰,王海峰表示,類似晶片代工廠,可以採用「集約化生產,平台化應用」的模式,即具有演算法、算力和數據綜合優勢的企業將模型生產的複雜過程封裝 起來,透過低門檻、高效率的生產平台,為千行百業提供大模型服務。這一產業化路徑已在文心大模型產業實踐中得到驗證,百度與各行業頭部企業、機構共建了包括能源、金融、航太、製造、傳媒、城市、社科以及影視等行業大模型。以文心一言等大語言模型為代表的人工智慧正深入千行百業,加速產業升級和經濟成長。